
Machine learning models are often dismissed on the grounds of lack of interpretability. There is a popular story about modern algorithms that goes as follows: Simple linear statistical models such as logistic regression yield to interpretable models. On the other hand, advanced models such as random forest or deep neural networks are black boxes, meaning it is nearly impossible to understand how a model is making a prediction.

Why rely on complex models?
The infosec industry is accustomed to rules, blacklisting, fingerprints and indicators of compromise — so explaining why an alert triggered is the natural next step. In contrast, machine learning models are able to identify complex non-linear patterns in large data sets, extrapolate answers and make predictions based on non-trivial compositions, making it nearly impossible to grasp its inner workings.
So if I can use simple expert rules, or regression/decision tree models that are interpretable, why should I use non-interpretable models? Well, because complex machine learning models are much more powerful.
For example, the next figure shows the implicit tradeoff between model performance, measured in accuracy, and model complexity, measured in number of parameters. This is built using the common MINST handwritten digits dataset, where the objective is to identify which number was written by looking only at the pixel values of each image.
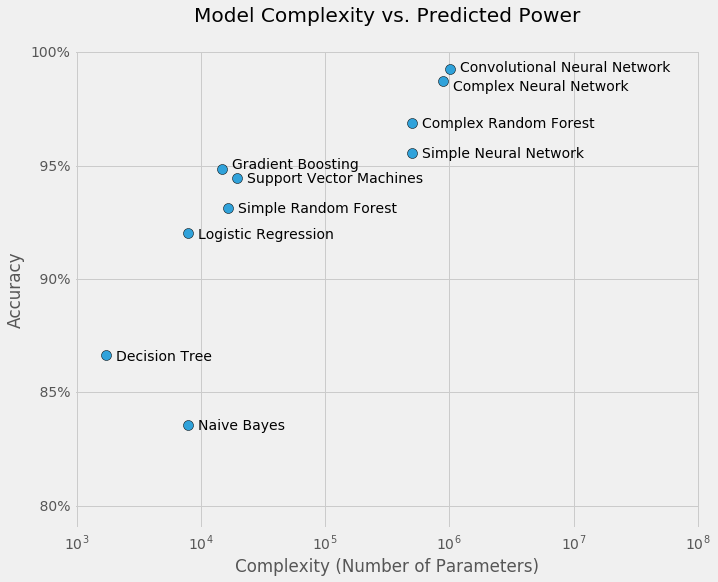
As a general rule, the more complex the model the higher its performance. In this case, using a simple interpretable decision tree yields an accuracy of 86 percent; on the other hand, a convolutional neural network has an accuracy of 99.3 percent. However, it must train more than a million parameters, compared with only 1,700 of the decision tree.
LIME in the limelight
Big efforts are being invested in finding ways to explain the output of machine learning models. Just over a couple months ago, a novel method called LIME was presented during the 2016 ACM’s Conference on Knowledge Discovery and Data Mining. LIME stands for Local Interpretable Model-agnostic Explanations, and its objective is to explain the result from any classifier so that a human can understand individual predictions.
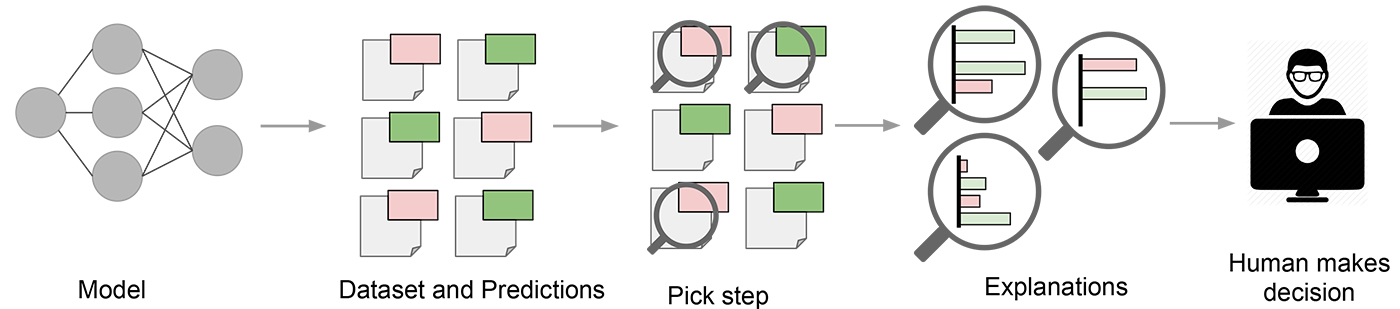
The LIME algorithm approximates the underlying model with an interpretable one. This is done by learning from alarms from the original example, and training a sparse linear model in the nearest neighborhood around the target instance. The example below shows how that is done.
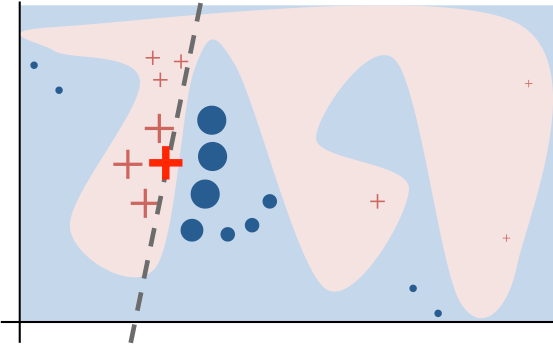
In the figure, the black-box complex decision function is represented by the blue/pink background. As expected, there is no easy way to generalize this non-linear model. However, if we look locally, we can extract linear explanations. LIME first selects the nearest neighbors to the prediction that we want to explain. These nearest neighbors are represented by the plus signs and circles. Afterward, we can fit an explainable linear model using only the selected instances, and use the coefficients of the linear model to explain a particular prediction.
This might sound confusing, but allow me to show a LIME example to explain the prediction of the Swordphish model.
Using LIME to Explain Swordphish Predictions
We recently made our machine learning-based Swordphish phishing URL prediction system, available through a public beta. Swordphish is a REST API backed by a set of extremely fast machine learning classifiers designed to predict with a high degree of confidence if a URL or domain is likely to be associated with phishing or malware command and control (C&C). Swordphish estimates approximately 50 features based on analyzing the structure of the URL, for example by estimating Kullback-Leibler Divergence between the normalized character frequency of the English language and the URL. Other features include the number of “@” and “-” symbols, the number of top-level domains in the URL, whether the URL is an IP address, the URL length and the number of suspicious words in the URL.
Afterward, Swordphish uses a Random Forest classifier that was trained with a total of 1.3 million parameters, and predicts the probability of an URL being a phishing site. As I pointed out above, understanding the prediction of such a complex machine learning model is nearly impossible. However, using LIME we can approximate the reasons behind how Swordphish makes individual predictions.
By way of example, we analyze some phishing URLs extracted from Phishtank, predict the probability of phishing using Swordphish, and understand the prediction with LIME:
URL: http://global.etrade.com.memberdirectory.quler.biz/member.do/
Swordphish prediction: 1.0

URL: http://203.131.143.34:9070/vk/volksbank.de/DesktopDefault.aspx/tabid=43%26tabindex=-1/index.htm
Swordphish prediction: 0.99
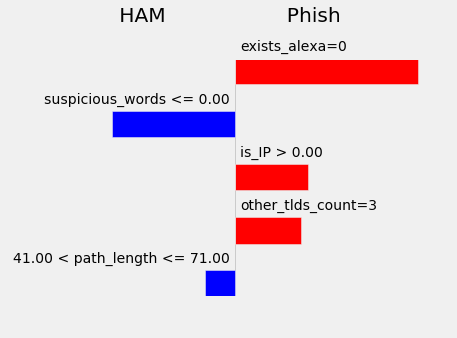
Finally, we look how Swordphish performs with a non-phishing URL that is not on the Alexa ranking
URL: http://www.integrityweb.net/en.asp?ac=ADI15948
Swordphish prediction: 0.31

Why it matters
With LIME, we can actually understand how Swordphish makes predictions without having to see the millions of parameters that the model has. In the first two examples, we’re looking at phishing URLs from Phishtank, and see why Swordphish is assigning both a very high probability of phishing. On the other hand, we look at a ham URL that is not on the Alexa ranking, and we see that the URL does not contain suspicious words, the length of the subdomain is short and it is not an IP. These indicators are the ones that Swordphish uses in order to give this URL a low phishing probability.
Using advanced methods such as LIME, we can gain a better understanding of how a machine-learning model works. That increased knowledge allows for a more robust fraud prevention strategy. Moreover, it’s critical to not only gain better insight on models, but it’s an effective way of assessing trust.
Article reposted with permission from Easy Solutions. Check the original piece.
