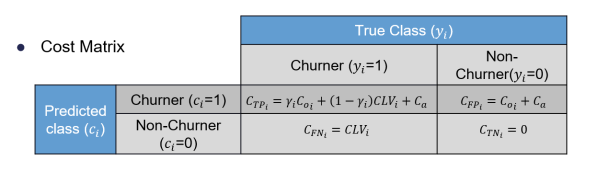
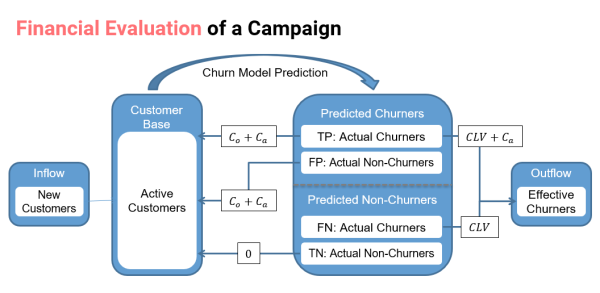
By Alejandro Correa and Maria Fernanda Cortes This post is part of a series in which I’m discussing several parts of my AI_at_Rappi presentation. In a previous post I discussed a particular algorithm for recommending restaurants called rest2vec, In a follow-up, I discussed how to include financial costs when analyzing a churn model. This time... Continue Reading →
Uplift Modeling